Python学习系列-Pandas 函数应用(apply/map)【上】
1、前言
经常使用 Excel 处理数据的朋友都知道 Excel 中包含很多实用的函数,比如 SUM、FIND 等,这些函数可以帮助我们批量计算或者处理数据,节省人工处理数据的时间,让 Excel 这个办公软件在初级数据分析领域拥有十分强大的存在感。而 Pandas 中也有着类似的函数,只不过 Excel 中的函数在 Pandas 中都变成了最简单基本的内容,因为在 Pandas 中,处理数据时不仅可以调用现成的函数,还可以根据需求自行定义函数并使用,这也让 Pandas 在个性化的数据处理中更具优势。不仅如此,由于 Pandas 背靠 Python,在函数应用中,我们还可以调用各种 API 服务来完成其他工具不可能的完成的操作,例如根据数据中“地址”字段得到对应地址的行政区划代码、经纬度等信息。本期文章我们就来学习一下 Pandas 中的函数应用。
本教程基于 pandas 1.5.3 版本书写。本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 中编写,本文分享的代码请使用 Jupyter Notebook 打开。
2、函数应用概述
单看前言部分的话,大家可能还不理解 Pandas 的函数应用能做什么,简单来说,本文要介绍的“函数应用”就是用来批量修改或生成表格中数据值的一种方式。这里的“批量”是指可以一次性操作整张表中的所有数据值,也可以操作数据行或数据列,其中最常见的还是操作数据列,即使用函数来一次性修改一列中的数据值,或者根据已有的数据列衍生出新的数据列。这样说可能会有些抽象,下面我们通过几个示范来了解一下具体的情况。
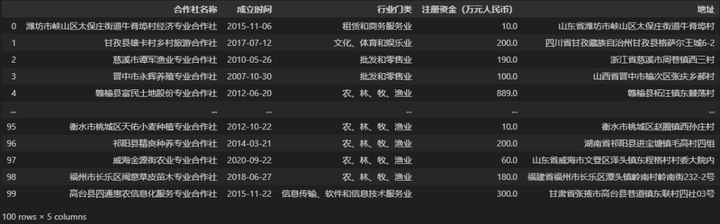
本文演示用的数据为 100 条农民专业合作社(截至2022年底)部分基本信息,读取后如下图所示。
通过应用函数,我们可以完成下面这些操作。
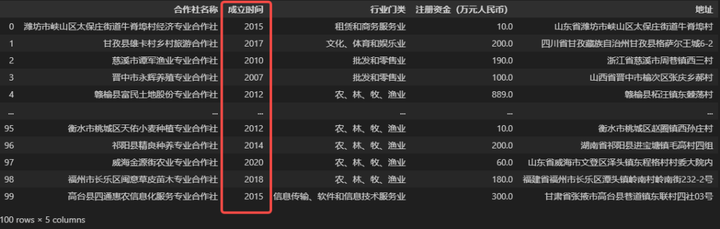
① 修改成立时间字段中的数据值,只获取其中的年份信息,得到下面的结果。
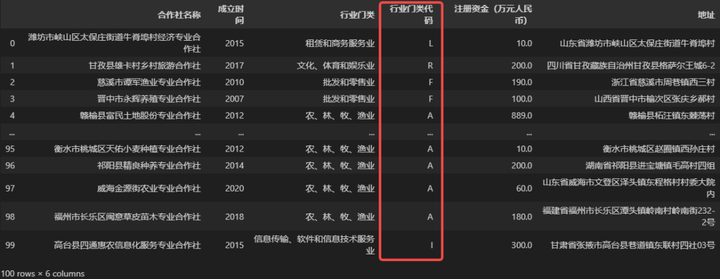
②行业门类字段看起来比较乱,我们再生成一个行业门类代码字段,这样就比较规范了。
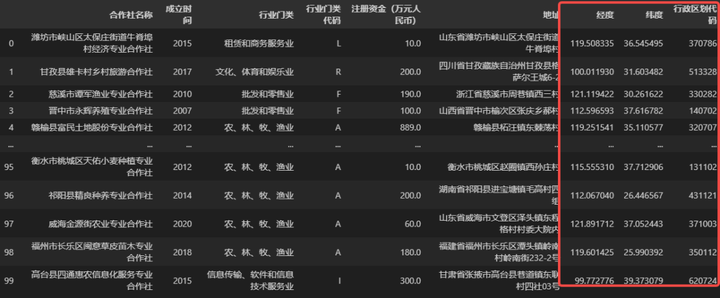
③ 仅从地址字段无法直接得到大量合作社的地域分布,那就使用函数多得到几个位置信息。
以上三个示范全部都是通过函数应用中修改原有字段或生成新字段,这也是在 Pandas 数据处理中最常使用的功能。除了上述应用,我们还可以根据自己的需要,完成个性化的任务,下面我们就来学习如何在 Pandas 中应用函数来实现上述功能。
3、Pandas 最自由的函数——apply
处理表格数据时经常需要连续处理多条数据,如果是在 Excel 中,一般先在一个单元格中使用函数,然后再向下应用就可以对多条数据进行同样的处理了。而在 Python 中,很多初入门者可能会比较习惯使用循环来处理数据,一次循环处理一条,这样就可以对整张表做处理了。
使用循环确实是一个好理解的方法,不过如果需要修改或生成字段时,熟悉 Pandas 的人使用最多的不是循环,而是apply()函数,原因有二。其一,在循环中循环体基本都是数据表(DataFrame)的行索引值,后续再根据索引值去取数据,最后才是计算和返回结果,这样做效率太低了,一次循环中大部分的时间都花在了根据索引值取数据这一步(Pandas 根据索引值取数据的性能不是很好),因此处理大数据集时就不太适合使用循环。其二,循环代码不够简洁,且复用性不强。以上这两点在apply()函数中都有改善,我们知道,函数可以让复杂的操作模块化,只需要定义一次,就可以应用在多个地方,而且运行速度也会更快,如果使用匿名函数的话,还会让代码变得更加简洁。
下面是apply()函数的常用参数列表以及各常用参数的用法和含义。
# 函数用法
<函数调用方>.apply(func, axis=0, result_type=None)
| 参数名称 | 参数可选值 | 参数含义 |
|---|---|---|
| func | 函数 | 应用在每一行或每一列的函数,函数可以是 Python 内置函数、第三方库中的函数、自定义函数或者匿名函数。 |
| axis | 0 或 1 | 函数应用的轴(方向),默认值为 0,表示应用在数据行,那么得到的也是数据行;如果为 1,表示应用在数据列,得到的结果就是数据列,这一点可以参考上文列举的例子。 |
| result_type | None、'expand'、'reduce'、'broadcast' | 当 axis 参数值为 1 时,此参数可调整返回结果的类型和样式。这些参数值理解起来十分困难,但用处又不大,这里笔者建议大家了解其中的 'expand' 即可,这也是最常使用的,会在下文中详细介绍。 |
apply()函数的使用方法还受到函数调用方的影响,在 Pandas 数据处理中,apply()的调用方可以是 Series 类型(数据列或行)或者 DataFrame 类型(数据表),而函数的返回值也可以是 Series 或 DataFrame 类型。我们可以将返回值嵌入到我们自己的数据中,这就有了上一节的操作。下面我们根据函数调用方的类型分别介绍 apply() 的用法。
事实上,Series.apply()函数与DataFrame.apply()是两个不完全相同的函数,虽然它们的名字和作用是一样的,但调用方的属性却不同,所以当apply()函数的调用方是Series类型时(即Series.apply()),其参数和上表中描述的参数完全不同(上表描述的是DataFrame.apply()的主要参数),不过使用方式要简单得多,下文我们举例介绍。
1、调用方为 Series
什么时候apply()函数的调用方会是一个 Series 呢?很简单,我们已经知道apply()函数的功能是根据已有的字段去修改原有字段或者衍生新的字段,当我们需要使用到的“已有的字段”只包含一个字段时,那么这个字段就是apply()的调用方,由于只有一个字段,所以一般都是一维 Series 类型。
先读取演示用的数据,读取数据的代码如下。
## 读取演示用的数据
# 参数 parse_dates 用于设置类型是日期的字段,设置后指定字段的读取结果为 datetime64 类型
data = pd.read_csv('./农民专业合作社数据样例100条.csv', parse_dates=['成立时间'])
data
比如说,我们想将注册资金(万元人民币)字段中的浮点数都转为整数,实际上就是根据已有的注册资金(万元人民币)字段去修改其本身。如何修改呢?我们可以使用 Python 的内置函数int()来实现,根据这个思路,我们就可以使用下面的代码。
data['注册资金(万元人民币)'].apply(int)
上述代码的返回值如下图所示。
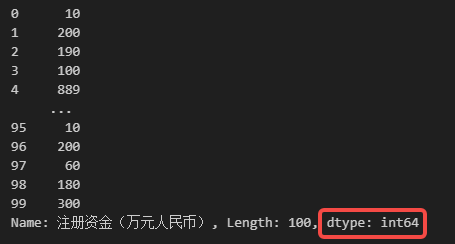
在上述代码中,apply()函数的调用方data['注册资金(万元人民币)']就是一个一维 Series,当调用方是 Series 时,只需向apply()传入一个必要参数func(要应用的函数)即可,这个函数就是上文中讲到的内置函数int(),需要注意的是,向func参数传递应用的函数时只需要书写函数的名称,不要在函数后面加括号。再来看上图所示的函数返回值,可以看到返回也是一个 Series,而且这个 Series 的名称和调用方完全一样。实际上,上述代码的内部流程就是使用传入的内置函数int()对调用方的每一个元素做处理并返回处理后的结果,也可以说是调用方中的每一个元素作为传入的函数int()的参数,例如转换前调用方的第一个元素是
10.0,在函数内部,会将int(10.0)作为这一元素处理后的结果(得到10),那么后续的其他元素都经过这样的处理后,再存储到与调用方一样的结构中,就得到了如上图所示的结果。
使用上述代码并没有达到目的,因为apply()函数会返回一个结果,但是并没有改变原始数据(即调用方),所以最后我们再将函数返回结果重新赋给调用方,那么原始数据就会被apply()函数的返回值替换掉,我们的目的也就达到了,代码如下。
# 应用 int() 函数, 并将返回结果赋给调用方(即修改原始数据)
data['注册资金(万元人民币)'] = data['注册资金(万元人民币)'].apply(int)
# 查看修改后的数据值
data
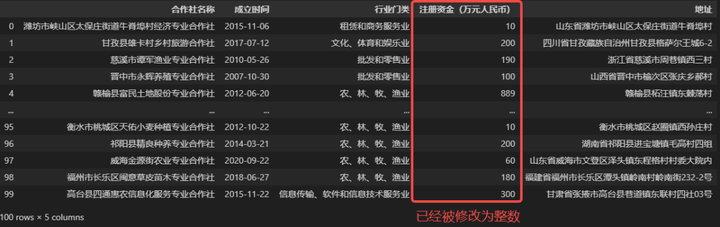
以上是apply()根据已有数据列修改数据列内容的一个示范,如果我需要根据已有的字段去衍生出一个新的字段,而不是修改原有的字段,要怎么做呢?也很简单,只需将返回结果赋给一个新字段即可,例如我想得到一个内容为整数的注册资金取整字段,但不修改原来字段的内容,可以使用下面的代码。
## 上一步中,原始的数据已经被修改,所以这里先重新读取数据
data = pd.read_csv('./农民专业合作社数据样例100条.csv', parse_dates=['成立时间'])
# 应用函数生成新的字段
data['注册资金取整'] = data['注册资金(万元人民币)'].apply(int)
# 查看处理后的数据
data
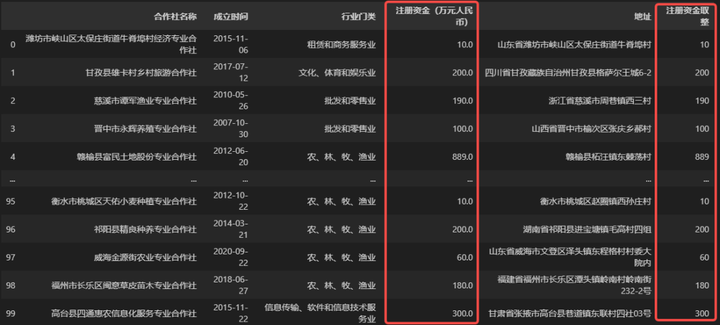
可以看到,在代码中,函数调用方依然是注册资金(万元人民币),因为即便是生成新字段,新的字段也是根据调用方中的值转化而来的。最后我们将函数的运算结果直接赋值给一个新字段,就成功地应用函数生成了一个字段,不过这种操作实际上是将一个apply()函数生成的 Series 追加到数据中才形成了新字段,所以新字段的位置一定是在数据最后面,如果需要在指定位置生成字段,可以先使用insert()函数在指定位置插入新的字段,再通过应用函数修改新字段的值。insert()函数的使用方法可见往期文章 Python 教学 | Pandas 表格数据行列变换 ,具体使用方式将在下一个案例中演示。
上面是一个应用内置函数实现修改和衍生字段值的例子,我们想将字段中的浮点数修改为整数,而内置函数int()刚好可以实现这一点。虽然 Python 中有不少实用的内置函数和第三方库,但我们的需求是千变万化的,不可能全部依赖现成的函数来完成任务,这个时候就可以根据具体的需要应用自定义的函数,这里的函数可以是自定义函数,也可以是匿名函数。如果我们的需求比较容易,一般使用匿名函数就可以了,优点是代码整洁易懂。例如我们需要根据成立时间字段得到一个成立年份字段,就可以使用下面的代码来实现。
# 重新读取演示数据
data = pd.read_csv('./农民专业合作社数据样例100条.csv', parse_dates=['成立时间'])
# 在“成立时间”字段后面(字段序号为 2 的位置)插入一个“成立年份”字段, 默认值设置为空字符 ''
data.insert(2, '成立年份', '')
# 应用匿名函数修改上述新增字段中的值
data['成立年份'] = data['成立时间'].apply(lambda x: x.year)
# 查看处理后的数据
data
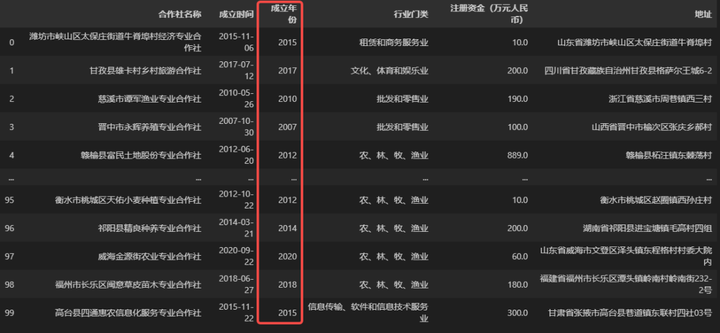
由于上述需求非常简单,只需要从成立时间字段中的日期中得到年份信息即可,所以应用了一个临时的匿名函数,如果大家对匿名函数不熟悉,那么还可以使用自定义函数来实现,只需将上面代码中应用函数的那一行代码替换成下面的即可。
# 先自己定义一个满足需要求的函数
def get_year(date):
return date.year
# 然后再 apply 中应用上述自定义函数
data['成立年份'] = data['成立时间'].apply(get_year)
可以看到,使用匿名函数一行代码就可以实现的任务,改用自定义函数后则需要使用至少三行。但并不是说一定要使用匿名函数,不要使用自定义函数,这当然是不对的,匿名函数的优势是简洁,适合处理简单的任务。当我们要做的事情有一定难度,需要多步处理或循环判断,那么就不能再使用匿名函数了,因为大量的代码都挤在一行中(匿名函数一般只占用一行代码)会导致代码没有可读性,这时自定义函数的优势就得到了体现。这一点我们在下一个例子中详细说明。
2、调用方为 DataFrame
在上文中我们讲到,apply()函数的功能是根据已有的字段去修改原有字段或者衍生新的字段,当这里的已有的字段只包含一个字段时,函数的调用方就是这个字段,也就是说调用方是 Series 类型。那么当我们需要根据已有的多个字段来衍生新字段时,调用方就不能是 Series 类型了,因为 Series 是一维数据,不可能包含所有要用到的数据值,所以上述情况中,调用apply()函数的对象就只能是表格类型 DataFrame,因为 DataFrame 可以包含多个字段供应用的函数去使用,下面我们通过一个例子来了解具体的情况。
在本文函数应用概述一节中,有这样一个案例:根据“地址”字段中的内容获取该地址对应的六位行政区划代码和经度、纬度值。Python 语言本身并没有根据地址获取经纬度等信息的功能,这里的实现原理是使用 Python 调用高德公司提供的
地理编码API来实现的,不过 API 是收费的,现在我们出于成本考虑,只需要获取注册资金在 100 (万元人民币,含100)以上企业的经纬度以及行政区划信息,这就要使用到数据中已有的两个字段,注册资金(万元人民币)和地址,下面我们先给出应用函数实现功能的代码。
# 导入 Python 网络请求模块
import requests
# 定义使用高德 API 进行地理编码的方法
def geocoding_by_address(address):
# 传入地址文本 address ,返回请求结果
# 使用高德 Web服务API 所需的 key, 需要前往高德开放平台申请
key = '************************' # key 隐藏,有需要的可以自行申请购买
# 发送地理编码请求的 url
url = 'https://restapi.amap.com/v3/geocode/geo'
# 向地理编码服务传入的参数
parameters = {
'key':key, # 使用服务所需的 key, 必需参数
'address':address, # 进行地理编码的地址,必需参数
}
# 使用上面定义的参数到指定 url 去请求数据
resp = requests.get(
url,
params=parameters
)
# 解析异常
resp.raise_for_status()
# 以 json 格式返回请求结果
return resp.json()
def GET_GIS_INFO(row):
DOM = row['地址'] # 取出地址
CAPITAL = row['注册资金(万元人民币)'] # 取出注册资金
if CAPITAL < 100:
# 若注册资本金小于 100,就不再使用 API,直接返回空值
return np.nan, np.nan, np.nan
try:
result = geocoding_by_address(DOM)
except:
result = ''
if result:
time.sleep(0.1)
if result['status'] == '1':
return float(result['geocodes'][0]['location'].split(',')[0]),\
float(result['geocodes'][0]['location'].split(',')[1]),\
result['geocodes'][0]['adcode']
else:
return np.nan, np.nan, np.nan
else:
return np.nan, np.nan, np.nan
data[['经度', '纬度', '行政区划代码']] = data.apply(GET_GIS_INFO, axis=1, result_type='expand')
# 展示衍生字段后的数据
data
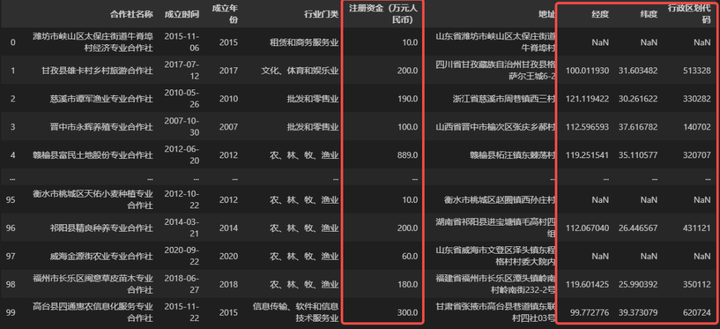
上述代码对于新手来说,并不是很好理解,下面笔者来做一个详细的解析。
首先,在上述代码中,有两个自定义函数geocoding_by_address和GET_GIS_INFO,其中前者是一个根据地址信息返回API请求结果的自定义函数;后者则是将要应用在表中,衍生出三个字段的自定义函数。在上述代码中,apply()函数的调用方是表格变量data,上文中我们提到,apply() 函数的内部流程就是使用应用的函数对调用方的每一个元素做处理并返回处理结果。如果调用方是一个字段,那么其中一个元素就是字段中的一个值,返回的处理结果就是新字段的值,这个很好理解,可是现在函数的调用方是表格(DataFrame),这是一个二维数据,这个时候调用方中的一个元素是什么呢?是一行,还是一列,还是表中的一个数据值?这个就要看apply()函数中的axis参数了,在文本的参数含义表中,我们说axis参数是控制函数应用的
轴,说简单点,就是用来控制apply()函数的处理对象,是一次处理一行数据,最后修改或生成的也是数据行?还是一次处理一列数据,最后修改或生成的是数据列?从上图来看,我们的目的是根据每一行中注册资金和地址,来生成经度、纬度、行政区划代码这三个字段,所以显然是后者。由于 axis 参数的默认值是 0 ,表示根据数据列生成数据行,所以我们要主动设置参数axis=1,具体可见上述倒数第二行代码。那么这样做之后,在apply()函数的工作过程中,一个元素指的就是函数调用方的一行数据了,注意这里的一行数据是一个 Series,这一步有点绕,笔者将其中一行数据抽出来方便大家理解。
## 取第 0 行数据,获取结果是一个 Series
data.loc[0, :]
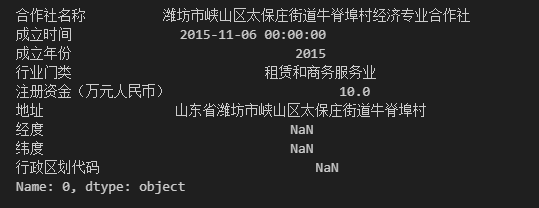
上图所示的就是上文中所指的“一个元素”,也是应用函数GET_GIS_INFO的参数,即上述代码中的形式参数row,参数传入后我们再根据实际需要提取出一个或多个的数据值,在这个例子中共提取了两个信息,一个是地址,取变量名为DOM;另一个是注册资金,取变量名为CAPITAL,具体可见函数GET_GIS_INFO中的前两行代码。
再看返回值,我们可以看到,在这一次函数应用例子中,我们要一次性生成三个字段,而前面的例子中都是修改或生成一个字段。根据代码可以知道,应用函数GET_GIS_INFO共有三个返回值,我们可能很自然地认为,当应用函数只有一个返回值时,就代表得到一列数据,而当应用函数有三个返回值时,就代表得到三列数据,而且最后的结果确实也是这样。事实上,我们最后能得到三个字段,是因为设置了参数result_type='expand',它表示将返回值中的每一个元素都转为一列(的其中一项)。熟悉函数的同学都知道,当返回值中包含多个元素时,返回值将会是一个元组,例如:
# 查看函数 GET_GIS_INFO 的返回值
GET_GIS_INFO(data.loc[1, :])
# 得到:
# (100.01193, 31.603482, '513328')
根据上面的代码可以知道,应用函数的返回值其实是一个包含了所有返回信息的元组对象,这么说的话,最后得到的不也是一个字段吗?确实如此,如果我们没有设置参数result_type='expand',我们将会都得到下面的结果。
# 不设置参数 result_type='expand'
data.apply(GET_GIS_INFO, axis=1)
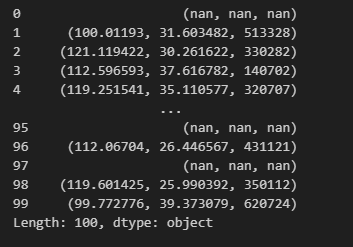
这样的话,apply() 函数的返回结果就是一个 Series,添加到数据表中的话,也只是一个字段。下面我们加上参数result_type='expand',看一看会得到什么结果。
data.apply(GET_GIS_INFO, axis=1, result_type='expand')
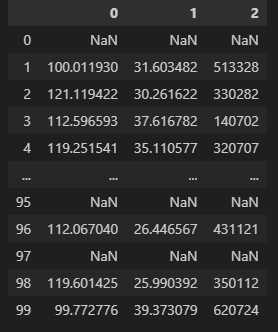
可以看到,添加参数后所得结果是一个包含三个字段的 DataFrame,我们可以将其视作一个包含 3 个字段的结果,最后我们再将这个结果赋给原始数据的三个字段就可以了,代码如下。
# 将得到的表格数据赋值给数据 data 的三个字段。
data[['经度', '纬度', '行政区划代码']] = data.apply(GET_GIS_INFO, axis=1, result_type='expand')
仔细观察这一行代码,需要注意的是,当需要表示数据中的多个字段时,必须使用两层括号。
以上就是apply()函数的调用方为 DataFrame,根据表中一到多个信息去生成多个字段的函数应用代码和代码解读。
使用apply()函数时,有一个点需要特别注意,那就是数据值的类型。文中提到,应用函数是对函数调用方的每一个元素做处理,那么如果一个字段中的数据值类型不统一,就极有可能在应用函数中出现问题。比如从成立时间字段中获取年份时,当这一字段的某处存在一个缺失值,那么我们就不可能从这个空值中得到年份。所以在编写应用函数时,一定要考虑要用到的所有数据值。
4、小结
本文介绍了 Pandas 中 apply() 函数的基本用法,apply() 函数是一个能够应用其他内置函数、第三方函数、匿名函数、自定义函数等可调用对象,批量修改和获取字段的实用型函数。相比较于使用循环处理表格数据,apply() 函数的速度快了很多,这将为我们处理数据节省大量时间,但同时这个函数的使用也有一定难度,所以笔者对代码进行了大量的解读。下期文章我们将继续介绍函数应用,学习更多的实用函数!