Apache Druid高效数据查询系统详细介绍
Apache Druid(孵化)是一个开源的分布式数据存储。Druid的核心设计结合了OLAP /分析数据库,时间序列数据库和搜索系统的创意,为广泛的用例创建了统一的系统。Druid将3个系统中每个系统的关键特性合并到其摄取层,存储格式,查询层和核心架构中。
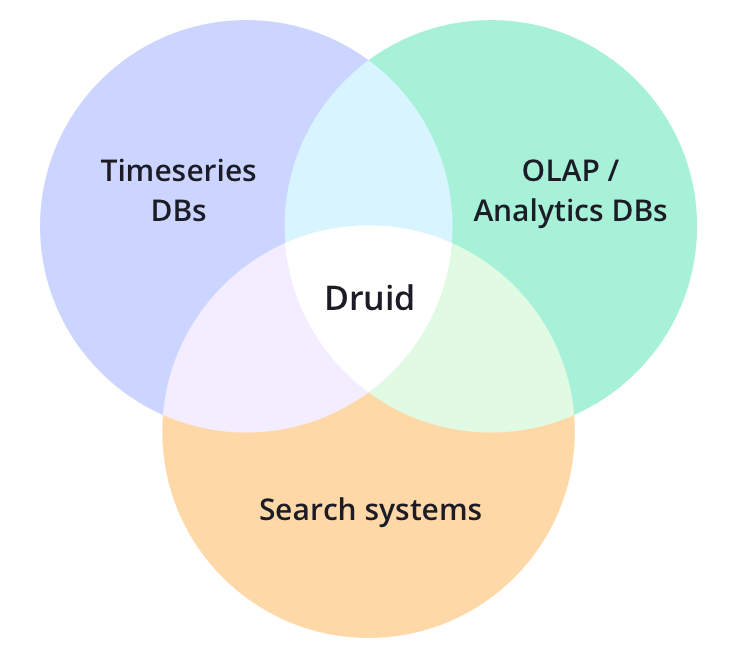
德鲁伊的主要特点包括
面向列的存储
Druid单独存储和压缩每个列,只需要读取特定查询所需的列,这些查询支持快速扫描,排名和groupBys。
原生搜索索引
Druid为字符串值创建反向索引,以便快速搜索和过滤。
流和批量摄取
适用于Apache Kafka,HDFS,AWS S3,流处理器等的开箱即用连接器。
灵活的架构
Druid优雅地处理不断发展的模式和嵌套数据。
时间优化的分区
Druid基于时间智能地划分数据,基于时间的查询比传统数据库快得多。
SQL支持
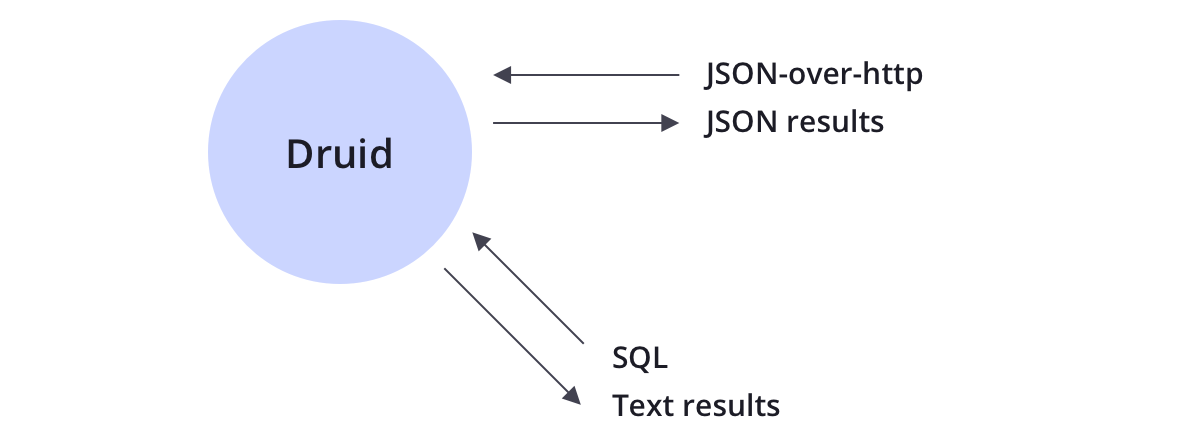
除了基于JSON的原生语言外,Druid还通过HTTP或JDBC讲SQL。
水平可扩展性
德鲁伊已经在生产中用于摄取数百万事件/秒,保留多年的数据,并提供亚秒级查询。
操作简便
只需添加或删除服务器即可向上或向下扩展,德鲁伊会自动重新平衡。容错架构围绕服务器故障进行路由。
积分
Druid是Apache Software Foundation中许多开源数据技术的补充,包括Apache Kafka,Apache Hadoop,Apache Flink等。
Druid通常位于存储或处理层与最终用户之间,并充当查询层以服务分析工作负载。
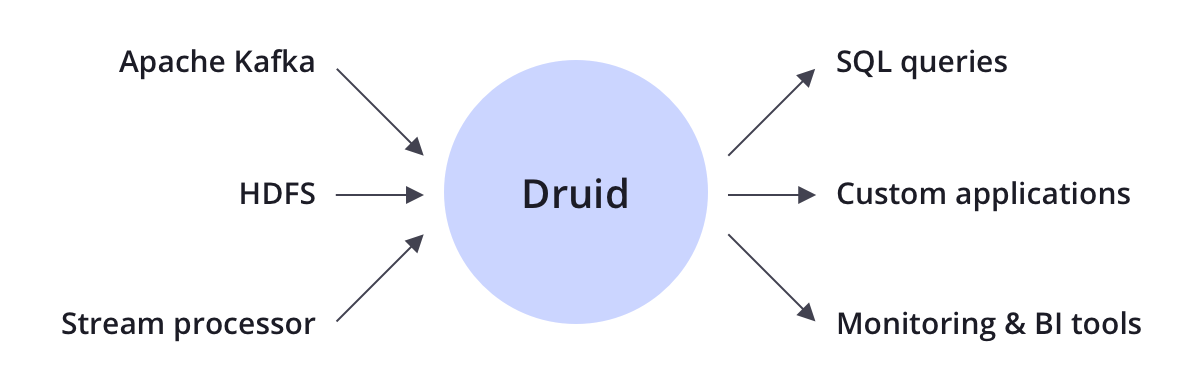
食入
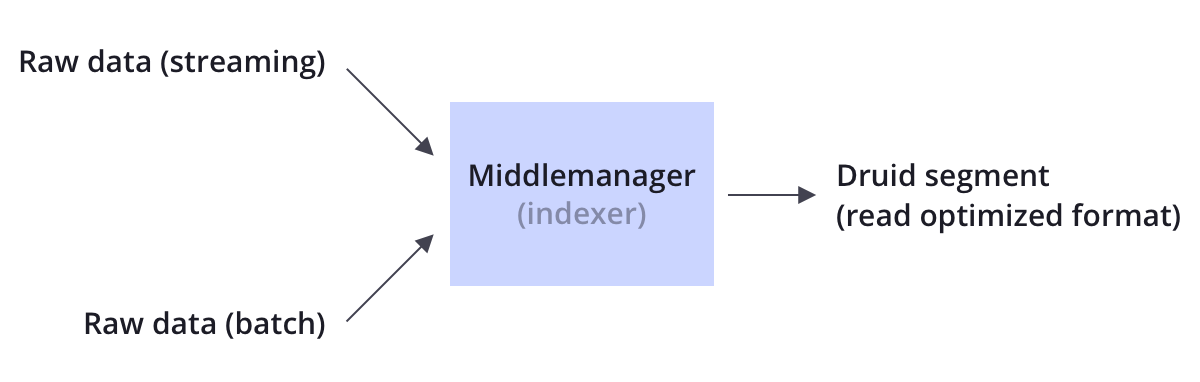
德鲁伊支持流媒体和批量摄取。Druid连接到原始数据源,通常是消息总线,如Apache Kafka(用于流数据加载),或分布式文件系统,如HDFS(用于批量数据加载)。
德鲁伊在一个称为“索引”的过程中将存储在源中的原始数据转换为更加读取优化的格式(称为德鲁伊“段”)。
有关详细信息,请访问我们的文档页面。
存储
与许多分析数据存储一样,德鲁伊将数据存储在列中。根据列的类型(字符串,数字等),应用不同的压缩和编码方法。Druid还根据列类型构建不同类型的索引。
与搜索系统类似,德鲁伊为字符串列构建反向索引,以便快速搜索和过滤。与时间序列数据库类似,德鲁伊会按时间智能地对数据进行分区,以实现快速面向时间的查询。
与许多传统系统不同,德鲁伊可以选择预先汇总数据。此预聚合步骤称为汇总,可以节省大量存储空间。
查询
Druid支持通过JSON-over-HTTP和SQL查询数据。除了标准的SQL运算符之外,德鲁伊还支持使用其近似算法套件的独特运算符,以提供快速计数,排名和分位数。
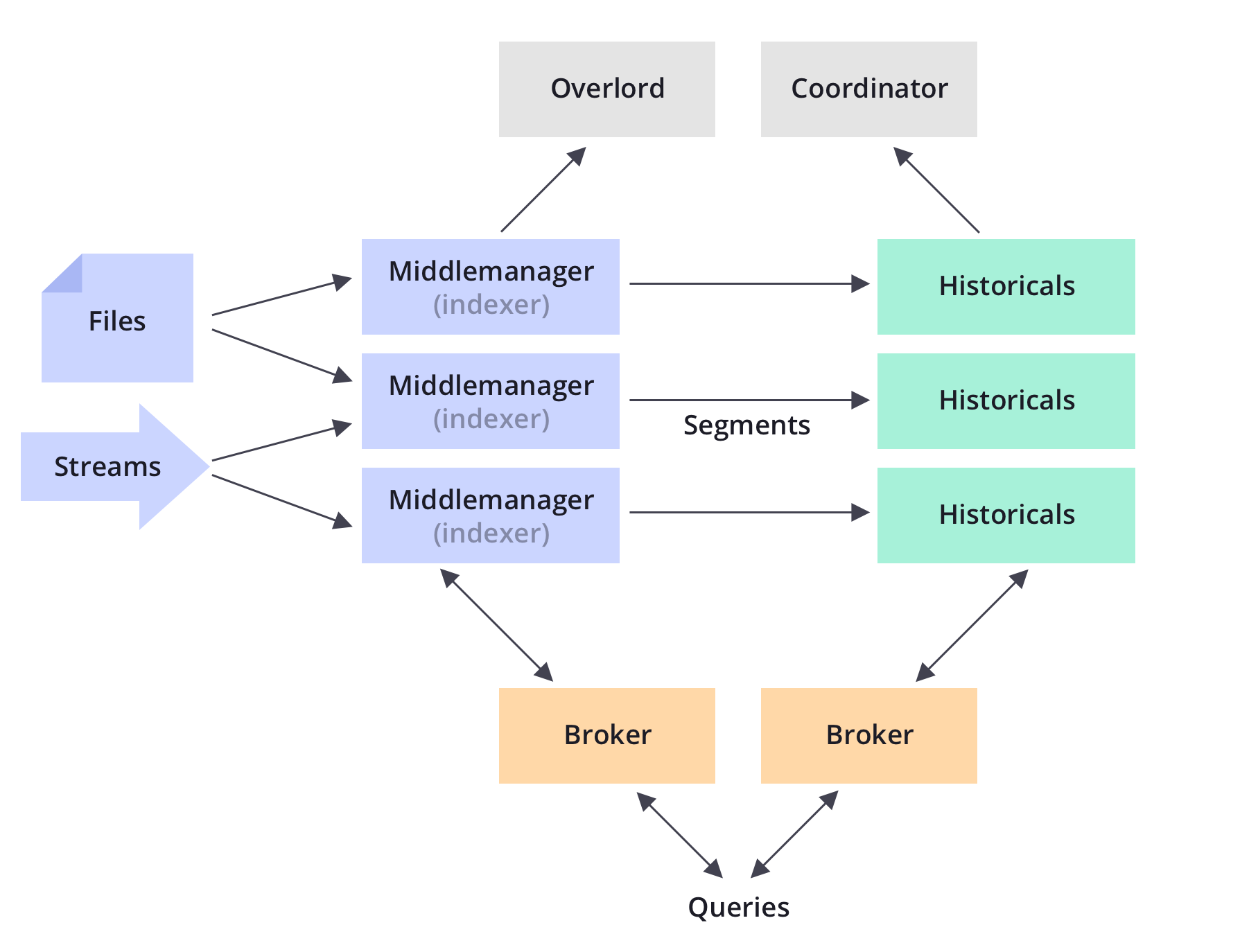
建筑
德鲁伊可以被认为是一个反汇编的数据库。德鲁伊的每个核心流程(摄取,查询和协调)可以单独或联合部署在商品硬件上。
Druid明确命名每个主要流程,以允许运营商根据用例和工作负载微调每个流程。例如,如果工作负载需要,操作员可以为Druid的摄取过程投入更多资源,同时为Druid的查询过程提供更少的资源。
德鲁伊过程可以独立地失败,而不会影响其他过程的操作。
操作
德鲁伊旨在为需要每周7天,每天24小时运行的应用程序提供支持。因此,德鲁伊拥有多项功能,以确保正常运行时间和数据丢失。
数据复制
Druid中的所有数据都被复制了可配置的次数,因此单个服务器故障对查询没有影响。
独立流程
德鲁伊明确指出其所有主要流程,并且每个流程都可以根据用例进行微调。流程可以独立地失败而不会影响其他流程。例如,如果摄取过程失败,则系统中不会加载新数据,但现有数据仍然可查询。
自动数据备份
Druid自动将所有索引数据备份到文件系统,如HDFS。您可能会丢失整个德鲁伊群集,并从此备份数据中快速恢复。
滚动更新
您可以通过滚动更新更新德鲁伊群集,无需停机,也不会对最终用户产生任何影响。所有德鲁伊版本都向后兼容以前的版本。